
The last Friday of each month is Pet Project day over here at Covve. Giving ourselves the time to experiment with new and exciting technologies, try out new approaches or just scratch that technological itch.
January’s pet projects ranged from a microservices monitoring cross platform app to reducing an O(n^2) project to O(n) and playing around with Google’s Tensorflow AI platform.
Michael: A microservices monitoring cross platform app
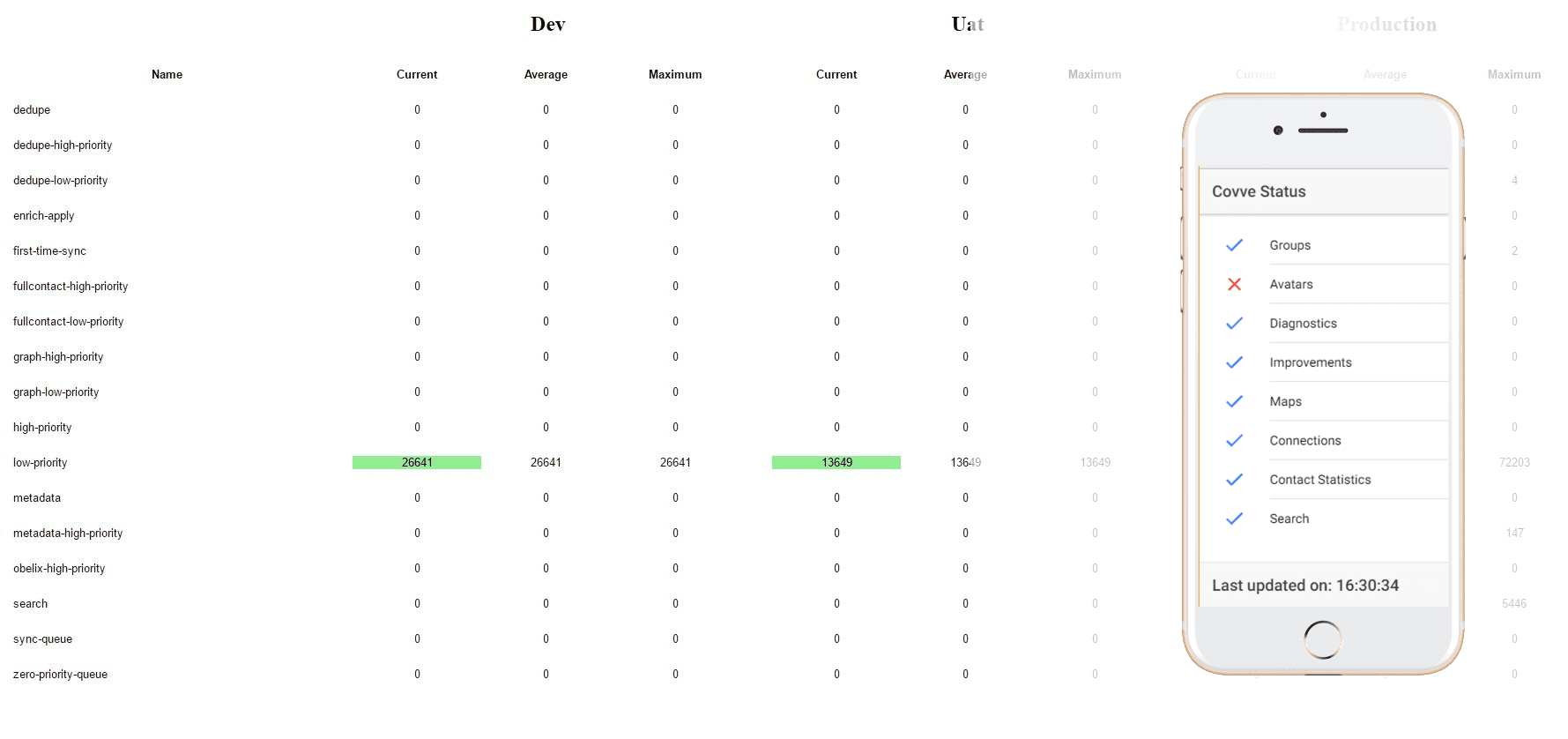
The entirety of Covve’s backend is built on a microservices architecture, something that has brought some significant benefits for us (read all about it here). Microservices do have some pain points however, and one of those is monitoring… being able to know exactly what is happening across tens of disparate and loosely connected services.
Michael’s pet project brought an elegant solution to this problem. A cross platform application written in Ionic 2 and Angular 2 that provides real-time monitoring of two core aspects of our microservices:
a) Service health: The health of each individual service, from our maps service which uses OrientDB to visualise our user’s interconnected networks of contacts to the groups service which is written in Node.js and runs on Docker
b) Queue size: Many of our microservices communicate with each other via Azure queues. For example, when a new contact is added, items are enqueued in the Search service’s queue for indexing the contact in Elastic search, in the dedupe service’s queue for finding duplicate contacts and the metadata service’s queue for identifying additional metadata for this contact. Monitoring the size of these queues allows us to spot bottlenecks, tweak scaling and identify issues
Full visibility and monitoring on a per-service basis. Absolute engineering bliss.
Next steps involve hooking this up to a service such as Pingdom for alerting the team out of hours as required.
Zafeiris: Reducing the complexity of de-duplication to O(n)
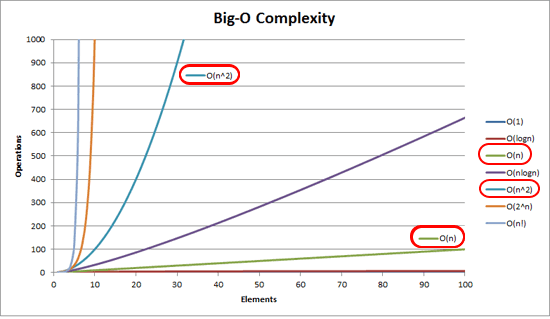
Algorithms, complexity and data structures have always been Zaferis’ pets, so he couldn’t resist tackling one of Covve’s process intensive services – the identification of duplicate contacts in a user’s address books.
Utilising an advanced proprietary algorithm tweaked over the course of the last three years, the deduplication service does a great job of identifying potential duplicated contacts and suggesting merges.
The previous implementation was of O(n^2) complexity - comparing all possible pairs of contacts, making it way more expensive to run as users’ addressbooks grow in size. This has necessitated both significant scaling of the deduplication servers as well as compromises on the frequency of deduplication checks.
Given the evolution of our understanding of real world data and recent refinements to Covve’s deduplication algorithms, it was now possible to use appropriate data structures that lead to a solution of linear running time cost with the overhead of additional linear memery cost (which is not a bottleneck or concern in this instance). This has brought a significant decrease in processing power (and cost) and increased responsiveness irrespective of address book size.
Our users and balance sheet will no doubt be happy.
Manolis: Consolidate logging platforms
Manolis took the opportunity to scratch an itch that was bothering him for a while. As Covve grew in 2016 we ended up using two separate and overlapping logging services, Logentries and Loggly.
Both offer a similar service and there is no reason to continue using both. Manolis consolidated our logging to Logentries. Removing our dependency on Loggly is making troubleshooting easier, reduces cost and simplifies the codebase.
Manolis 1 – Annoying Itch 0
Valadis: A peek into Google’s TensorFlow

Inspired by a recent workshop with Google, and our increasing focus on machine learning, Valadis took the first steps in investigating the potential of Google’s TensorFlow platform and its applicability to Covve.
Already in partnership with AI experts Helvia.io, 2017 brings an increased focus on machine learning, big data and data science in Covve. We believe that strategically employing such techniques can bring some unique advantages to our users.
So, watch this space for some exciting new features later this year!
Comments